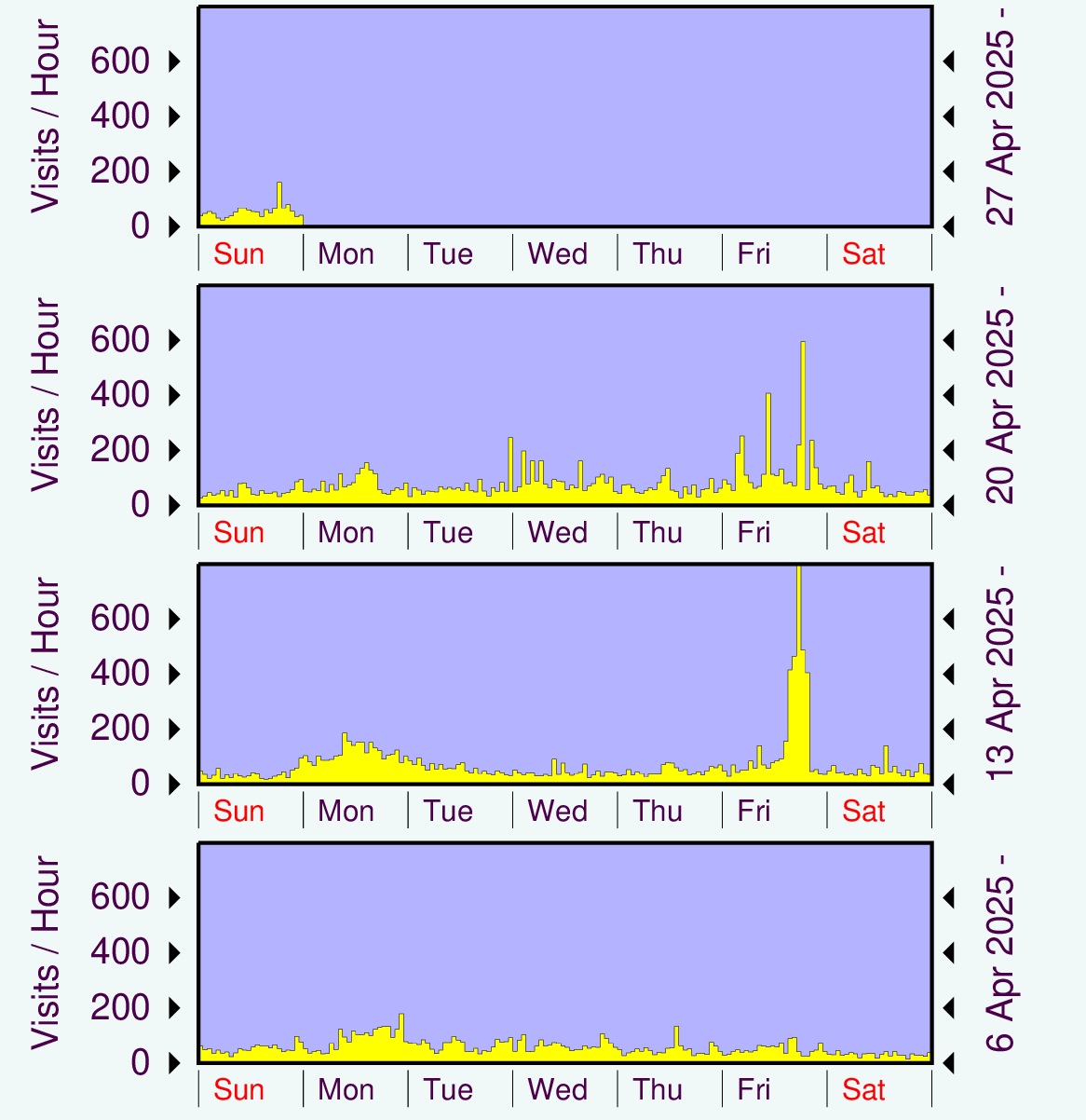
|
- A file is listed once, including those with multiple URL's.
(E.g., www.ece.lsu.edu/koppel, www.ece.lsu.edu/koppel/,
www.ece.lsu.edu/koppel/koppel.html, www.ece.lsu.edu/koppel/index.html.)
- Image and other files likely to be embedded in pages are omitted.
This way, the lists aren't cluttered with hits to icons,
latex2html gifettes, and the like.
- Hit counts for each file are given for hits from within LSU,
outside LSU, and by possible robots (Bots?). (The command line version
provides a fourth category, intended for your own host, [Me]).
The hit counts omit page reloads, so the numbers are not
inflated by visitors moving back and forth between pages.
- The list of top accessors is resolved to the departmental level
within LSU and to the institutional level outside LSU (assuming
certain domain naming conventions, which don't always hold).
This provides more useful information and protects privacy.
- Hits may originate from links on static pages, links from
search-result pages, and other sources. The hosts from which
the most static link hits originated from are listed (Most Frequently
Referring Hosts).
- Some hits are from links generated by a search engine.
The most common search strings are listed (Most Frequently Used
Search Strings) along with the last page they hit. (The same
search string might hit several pages, only the last page hit is listed.)
This data is based upon a guess of how search result hits appear,
so the data is not exact. (Some search strings might not appear
and some items in the list might not be search strings.)
The most commonly used browsers (user agents) are listed. These
are listed by brand and version, with some non-browsing agents
omitted. The brand is the name by which the browser is known, for
example, MSIE (Microsoft Internet Explorer), Netscape (Netscape
Navigator), or the name under which it will soon be known, SeaMonkey.
Robots and link checking tools are omitted
from the list (at least the ones that can be identified) but, for now,
page copying tools are included. The percentages are for browsers
included in the list. Because of the variety of ways browsers identify
themselves some browsers may be misidentified, misclassified, or omitted.
If a brand has more than one version then the percentage of hits for
that brand from each version is given. Versions are clustered
together so that instead of separately listing, say, 1.0, 1.0.1,
1.0.1a, 1.0.1ntfix, they are shown as 1.0x. If the clustering results
in only one version the clustered versions are shown separately. As
with brands, version numbers are not always correctly determined.
An attempt is made to keep the frequent browser information correct.
| |