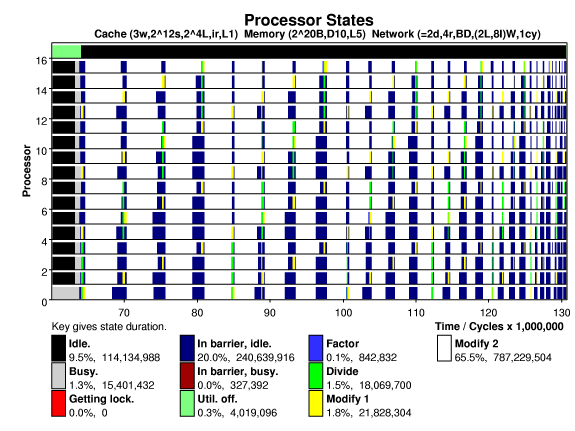
The plot below shows processor states versus time on a 16-processor system running the Splash-2 LU factorization program on a 512 by 512 matrix (the base problem size). Each processor has a 3-way, 2048-set, 16-byte line set associative cache. A directory based cache coherence scheme is used. The system is interconnected by a 2-D mesh, links can transfer two bytes in the time needed to execute an instruction (cycle).
The top bar (above 16, starts green) indicates whether the program is in the statistics collection region, green indicates off, black indicates on. The other bars show processor states; the state is determined by the execution of state switches placed in user and system code. State descriptions are shown in the key. The factor, divide, modify 1, and modify 2 states are specific to LU, the others are system states. The modify 2 state contains the "daxpy" loop.
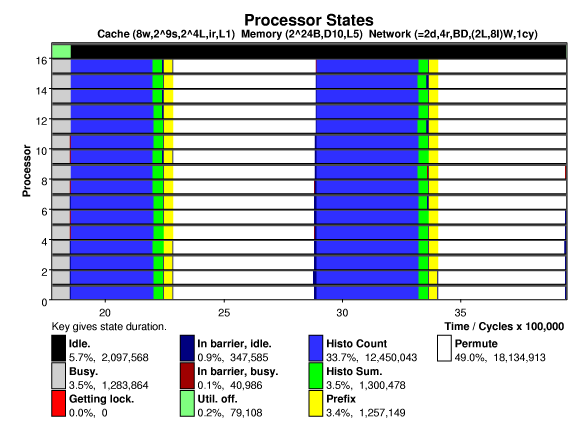
The plot below shows processor states versus time on a 16-processor system running the Splash-2 radix sort on 262144 keys, (the base problem size). Each processor has a small 8-way, 512-set, 16-byte line set associative cache. A directory based cache coherence scheme is used. The system is interconnected by a 2-D mesh, links can transfer two bytes in the time needed to execute an instruction (cycle).
A modified prefix sum algorithm is used, giving better performance on the systems tested. Note the high utilization and that the potentially troublesome global bin sum and parallel prefix operations take only a small fraction of execution time.
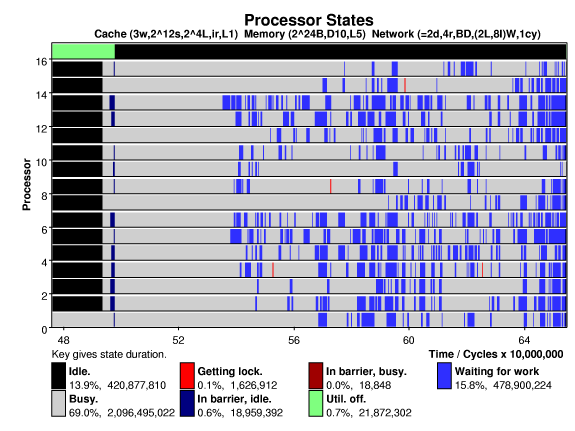
The plot below shows processor states versus time on a 16-processor system running the Splash-2 Cholesky factorization on the tk29.O input file, the base problem size Each processor has 3-way, 4096-set, 16-byte line set associative cache. A directory based cache coherence scheme is used. The system is interconnected by a 2-D mesh, links can transfer two bytes in the time needed to execute one instruction (two unscaled cycles).
States here do not indicate just what Cholesky is doing, just that it's busy. Cholesky uses a work queue to distribute work to processors, the "waiting for work" state is active when a processor is waiting for something to be placed in the queue. Note that Cholesky makes use of locks (semaphores) rather than barriers to control access to shared memory, as can be seen by the red segments.
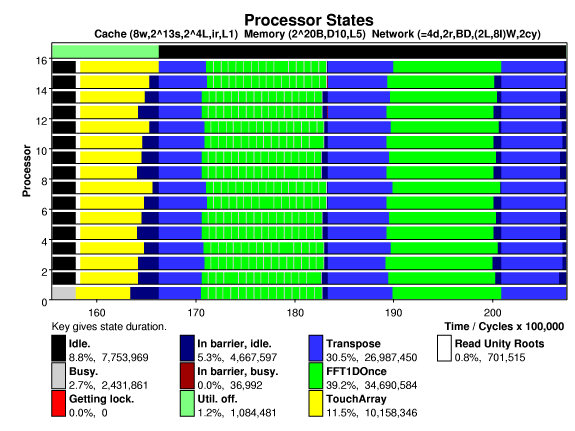
The plot below shows processor states versus time on a 16-processor system running the Splash-2 FFT on 65536 numbers, (the base problem size). Each processor has 8-way, 8192-set, 16-byte line set associative cache. A directory based cache coherence scheme is used. The system is interconnected by a 2-D mesh, links can transfer two bytes in the time needed to execute two instructions (two unscaled cycles).
Note that the statistics collection is in the TouchArray state, which warms the cache. (Statistics collection does not refer to the statistics used for these graphs.)

| David M. Koppelman - koppel@ece.lsu.edu | Modified 28 Nov 2007 18:31 (031 UTC) |