EE 4720 Computer Architecture - HW 6 Solution (Spring 1998)
|
In the execution below, the branch outcome is not available when
the branch instruction reaches ID, at cycle 4, and so it waits in a
reservation station. The system predicts the branch as taken and so
fetching starts at the branch target in cycle 5. (If the system had
an IF-stage branch target buffer it would have been possible to fetch
the target at cycle 4, eliminating a cycle of delay.) Instructions at the
target are executed speculatively, that is they don't do anything that
can't be undone. The branch condition is finally available at cycle
11, the speculatively executed instructions are deleted from the
reorder buffer and fetching starts at the target in cycle 12. | |
sub r4, r5, r6 IF ID 3:EX 3:WB
Cycle 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
multf f4, f5, f6 IF ID 1:M1 1:M2 1:M3 1:M4 1:M5 1:M6 1:M7 1:WB
addf f0, f1, f2 IF ID 6:A1 6:A2 6:A3 6:A4 6:WB
eqf f0, f3 IF ID 7:RS 7:RS 7:RS 7:A1 7:A2 7:A3 7:A4 7:WB
bfpt TARG IF ID 2:RS 2:RS 2:RS 2:RS 2:RS 2:RS 2:BR 2:WB
add r1, r2, r3 IF x IF ID 2:EX 2:WB
sub r4, r5, r6 IF ID 3:EX 3:WB
...
TARG:
and r1, r2, r3 IF ID 3:EX 3:WB
or r4, r5, r6 IF ID 4:EX 4:WB 4:WB
...
|
Execution notes: With dynamic execution load and store instructions
use their own functional units, so other instructions do not
pass through the MEM stage. The stage labeled
WB is actually a write to the common data bus which
will write into any waiting reservation stations or functional
units (as would happen in cycle 7 when addf completes) and also
into the reorder buffer. The data is written to the register
file when the instruction is retired from the reorder buffer.
| |
|
The reorder buffer contents are shown by cycle below. An entry
for a cycle includes instructions that are inserted during that cycle
and instructions that will be removed at the end of the cycle. The
reorder buffer fills until cycle 9 as instructions wait for
multf to complete, after that instructions up to the
branch retire one-by-one. (To be retired [as opposed to being deleted]
from the reorder buffer an instruction must be the least-recent entry
[the bottom entry as illustrated below] and must have completed
execution [indicated by a  ]).
The branch condition is resolved in cycle
11, since the branch was mispredicted the speculatively executed ]).
The branch condition is resolved in cycle
11, since the branch was mispredicted the speculatively executed
and and or instructions are removed from the
reorder buffer and fetching is restarted at the add
instruction. The pipeline and reorder buffer might contain
instructions before multf and after sub and
or, these are omitted for clarity and to save time.
| |
|
Cycle
Reorder
Buffer
Contents |
0
(Empty*) |
1
multf |
2
addf
multf |
3
eqf
addf
multf |
4,5
bfpt
eqf
addf
multf |
6
and
bfpt
eqf
addf
multf |
7
or
and
bfpt
eqf
addf
multf |
8
or
and
bfpt
eqf
addf
multf |
9
or
and
bfpt
eqf
addf
multf |
| |
|
Cycle
Reorder
Buffer
Contents |
10
or
and
bfpt
eqf
addf |
11
or
and
bfpt
eqf |
12
bfpt |
13
add |
14
sub
add |
15
sub
add |
15
sub |
16
(Empty*) |
| |
|
*Empty of any instructions included above.
Completed execution. | |
|
The branch behavior here is very easy to determine: the branch
will not be taken in the first 16 iterations then taken in the
next 16 iterations, after which the cycle repeats.
| |
add r1, r0, r0
LOOP:
andi r2, r1, #0x10
beqz r2, CONTINUE
addi r3, r3, #1
CONTINUE:
addi r1, r1, #1
j LOOP
|
To determine the branch prediction accuracy the value of the
branch history counter at each iteration is needed. The counter value
is initially 0, it's incremented in the first 16 iterations though it
saturates at 7. During the second 16 iterations the counter is
decremented, reaching zero by the beginning of iteration 23, and
remaining at zero through iteration 31. Note that these are the values
of the counter before the branch executes, which of course
is used for prediction. As with the branch
outcome, the branch history counter value also repeats. The table
below shows the counter values, prediction, outcome, and number of
correct predictions by iteration. At the beginning of iteration 32 the
BHT counter is zero, since the branch behavior repeats every 32 cycles
the prediction behavior will also repeat. The branch prediction
accuracy is the number of correct predictions divided by the number of
predictions, 24/32 = 0.75. | |
| Iteration | Count Value | Prediction | Outcome | Num. Correct |
| 0-4 | 0-4 | NT | T | 0 |
| 5-7 | 5-7 | T | T | 3 |
| 8-15 | 7 | T | T | 8 |
| 16-18 | 7-5 | T | NT | 0 |
| 19-23 | 4-0 | NT | NT | 5 |
| 24-31 | 0 | NT | NT | 8 |
|
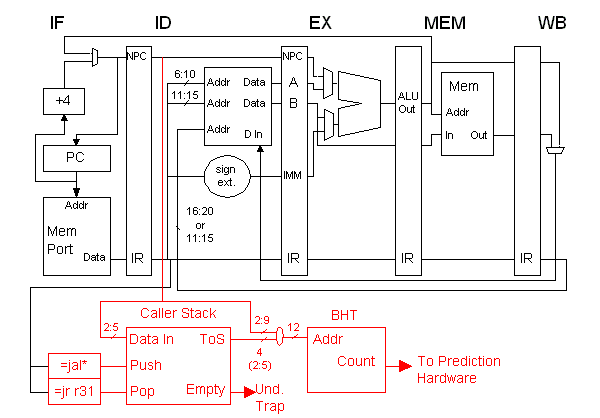
The solution is shown in the figure below, with additions in red.
Not shown are details of the stack implementation, clocking inputs for
the BHT, hardware to support context switches, prediction and target
address hardware. | |
|
The key to solving the problem is choosing the correct address
for the branch history table (BHT) because the branch predictor
matches a particular history (counter value) with a particular address.
Normally, the BHT is addressed
with the branch instruction's address, so that each branch
instruction has its own history (ignoring collisions). In the problem
a branch predictor is to be designed that also takes into account the calling
procedure. Therefore, the BHT address must be constructed using something
that could identify the calling procedure; that something is the return
address that is saved in r31 by the jal and
jalr instructions. (The return address is available in the
IF/ID.NPC register when the call instruction is in ID.)
| |
|
In the solution above, part of the most-recent calling address is
available at the ToS (top of stack) output of the Call Stack box.
That is combined with the branch instruction address to construct a
BHT address. Because DLX instructions are aligned, bits 0 and 1 from
both addresses are omitted (since they would always be zero, and if
included would leave 75% of the BHT unused). Four bits (2:5) are
taken from the calling procedure address and eight bits from the
branch instruction (2:9), for a total of 12 bits. Only four
calling-address bits are included because the number of different
places that a procedure can be called from would be much smaller than
the number of branch instructions in the program. As with an ordinary
BHT and especially with a correlating predictor there will be
collisions in the BHT, that is, multiple branch instructions will use
the same entry. This is acceptable because it doesn't happen too
often and the consequences of a collision is only misprediction, not
incorrect execution. Note that multiple branch instructions with
identical address bits 2:9 would not collide in the BHT if the
calling address bits 2:5 were all different. | |
|
The box labeled Caller Stack stores bits 2:5 of the addresses of
assumed procedure call instructions. Whenever a jal or
jalr instruction is in ID, the instruction address is
pushed on the stack, it will appear at the ToS (top of stack) output
in the next cycle. When a jr r31 instruction, the
assumed procedure return, is in ID the stack is popped. (That is, the
most recently pushed address is removed and the next-most-recent one
is moved to the top-of-stack position.) If the stack is empty the
empty line is asserted, which might trigger a trap. (The
operating system might fill the stack with data that had overflowed
when too many items were pushed.) | |
|
As with all chapter-3 DLX implementations, there is no actual reason
to predict branches since the branch condition is available early.
The chapter-3 DLX implementation was used above for simplicity.
| |
|
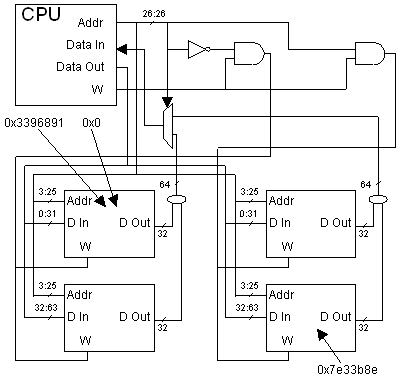
The connections and address locations are shown below.
| |