
Instruction-Level Parallelism
Since ISA is defined in terms of one-at-a-time execution ...
... programs have ILP by "accident".
In other types of parallelism ...
... programmer (or compiler) specifies multiple paths of execution ...
... each with its own program counter (or thread).
ILP is between instruction in a single thread (using a single PC).
ILP is a property of programs ...
... which hardware may not be able to fully exploit.
Dependency
Let A and B can be two instructions ...
... with B following A ...
... by any distance.
If instruction B depends on instruction A ...
... A must execute before B ...
... unless special measures are taken.
Special measures are not always possible.
Three (or Four) Dependency Types
Name Dependencies
Control Dependency
Data or True Dependencies
Not practical for HW to remove this dependency.
Akin to RAW hazard.
Name Dependencies (Two Kinds)
Obviously, A must read before B writes.
Akin to WAR hazard.
Output dependence:
A must write before B.
Akin to WAW hazard.
Control Dependencies
B is control dependent on A if B being executed depends on A.
Hazards v. Dependencies
... but a hazard is a property of pipelines ...
... while a dependency is a property of instruction streams.
Pipeline will stall if ...
... there is a dependency between instructions ...
... and a corresponding hazard in pipeline.
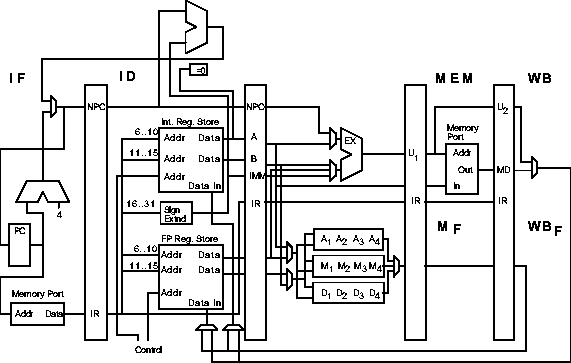
DLX Pipeline For Chapter 4
Uses branch hardware described in section 3.5 ...
... and so branch delay is only one cycle.
All FP units are fully pipelined and each uses 4 stages.
A FP memory and write-back stage are added ...
... called MF and WBF
Bypass paths (not shown below) are included.
See loop example for details.
Loop Example
for( i=40320; i>0; i--) a[i]+=c;
In DLX assembler
LOOP: LD F0, 0(R1) ADDD F2, F0, F4 SD 0(R1), F2 SUBI R1, R1, #8 BNEZ R1, LOOP
Note that no real compiler would start array at address 8.
SUBI R2,R1,R3, where R3 contains
the address before the first element. The branch would test R2 instead
of R1.
Execution On Pipeline.
Time 0 1 2 3 4 5 6 7 8 9 10 11 12 LD IF ID EX MEM WB IF ID EX ADDD IF ID A1 A2 A3 A4 MF WBF IF ID SD IF ID EX MEM WB IF SUBI IF ID EX MEM WB BNEZ IF ID EX MEM WB
The data provided by LD for ADDD will not be available until after LD finishes MEM, so at cycle 3 ADDD stalls.
SD needs its data, produced by ADDD, at the beginning of MEM, so MEM is delayed until cycle 8.
BNEZ first tests the branch condition when in ID at cycle 8. The condition is being computed by SUBI in cycle 8 and so won't be available to BNEZ until cycle 9.
Because there are separate memory and writeback stages for integer and floating-point operations, ADDD and SD can execute as in cycles 8 and 9. If instead the pipeline were designed so that the integer and FP operations used the same memory and WB stages, the SD instruction would be stalled.
The second iteration is shown in green.
The loop loops with the fetch of the branch target, LD, in cycle 10 ...
... and so the loop takes 10 cycles per iteration.
Dependencies in Loop
... in addition to control and anti dependencies.
True dependencies limit the ways instructions can be rearranged ...
... and so limit performance improvement attainable ...
... by rearranging instructions to avoid stalls.
As will be shown in section 4.2 ...
... hardware can correctly execute instructions out of order ...
... even when output- and anti-dependencies are violated
However, order determined by true dependencies must be maintained.
Therefore, hardware can't do much with loop above
Simple (and limited) Change to Loop
LOOP: LD F0, 0(R1) ADDD F2, F0, F4 SUBI R1, R1, #8 SD 8(R1), F2 ! Displacement compensates for movement of SUBI. BNEZ R1, LOOP
Execution of the loop:
Time 0 1 2 3 4 5 6 7 8 9 10 11 12
LD IF ID EX MEM WB IF ID EX MEM WB
ADDD IF ID A1 A2 A3 A4 MF WBF
IF ID A1 A2
SUBI IF ID EX MEM WB IF ID EX
SD IF ID EX MEM WB IF ID
BNEZ IF ID EX MEM WB IF
Here SD stalls for one rather than two cycles.
The condition is ready for BNEZ when it enters ID, so it doesn't stall there.
The branch target is computed at the end of ID so that fetching the first instruction of the next iteration can start ...
... in cycle 7 using aggressive hardware ...
... or cycle 8 using conservative hardware. (Hint: Because of the stall.)
The second iteration is shown in green.
The second execution of ADDD starts in cycle 8 (shown on a separate line to save space) even before the first execution finishes.
This change improved performance slightly but any further improvements are limited by true dependencies.
To give the hardware maximum flexibility compilers and programmers need to avoid unnecessary true dependencies.
The index in the loop (i or R1) is the culprit here.
Some true dependencies can be removed using a technique called loop unrolling.
Loop Unrolling
for(i=40320, i>0; i-=8){
a[i]-=c; /* line 2 */
a[i-1]-=c; /* line 3 */
a[i-2]-=c; /* line 4 */
}
There are no true dependencies between any pair of statements in body, so they can be executed in any order.
As a bonus, index arithmetic and testing is done 1/3 as often.
Loop Unrolling In Real Life
... number of iterations must be divisible by three ...
... or unrolled loop must be followed by 1 or 2 copies of body:
for(i=40343, i>16; i-=8){ /* Loop index not divisible by 3. */
a[i]-=c; /* line 2 */
a[i-1]-=c; /* line 3 */
a[i-2]-=c; /* line 4 */
}
a[8]-=c;
a[16]-=c;
Fortunately, this tedium is handled by compilers.
Execution of Unrolled Loops
LOOP: LD F0, 0(R1) ADDD F2, F0, F4 SD 0(R1), F2 LD F0, -8(R1) ADDD F2, F0, F4 SD -8(R1), F2 LD F0, -16(R1) ADDD F2, F0, F4 SD -16(R1), F2 SUBI R1, R1, #24 BNEZ R1, LOOP
If the hardware could handle anti-dependencies (e.g., on F0) ...
... then it could execute the three loads first ...
... then the three adds, the subtraction, three stores, and finally the branch.
All of this would be done without adjusting instructions.
Scheduling Instructions in Unrolled Loop By Hand
... and could not start instructions out of order.
So there would be many stalls executing unrolled loop above.
For such pipelines the code can be scheduled (rearranged) to avoid ...
... every stall but one.
LOOP: LD F0, 0(R1) LD F10, -8(R1) LD F20, -16(R1) ADDD F2, F0, F4 ADDD F12, F10, F4 ADDD F22, F20, F4 SUBI R1, R1, #24 SD 24(R1), F2 SD 16(R1), F12 SD 8(R1), F22 BNEZ R1, LOOP
Note that registers were renamed to remove name dependencies.
Dynamic Scheduling
... is said to use dynamic scheduling.
Two dynamic scheduling techniques described in text ...
... scoreboarding ...
... and Tomasulo's Approach.
Scoreboarding Overview
... a functional unit (e.g., DIV) is available ...
... and there is no executing instruction that will write same register.
(E.g., ADDD F0,F2,F4 would wait if
MULF F0,F6,F8 were executing.)
Instructions wait in functional units ...
... until all their operands are available ...
... then they read them and start executing.
Instructions wait at functional unit outputs ...
... long enough to avoid any WAR hazards ...
... before proceeding to write their results.
In scoreboarding implementation described in book ...
... functional units are not pipelined ...
... instructions proceed from FUs directly to writeback.
Information to manage execution is stored in a central structure ...
... called a scoreboard.
The system using scoreboarding can execute instr. out of order ...
... but will stall when faced with name dependencies.
Tomasulo's Approach Overview
... can rearrange instructions ...
... despite name dependencies.
Each functional unit has one or more reservation stations.
A reservation station may be ...
... empty ...
... holding a waiting instruction ...
... or holding an executing instruction.
Each reservation station is given a unique number ...
... used to identify future result of held instruction.
For example, consider:
DIVD F0,F2,F4 ADDD F6,F8,F0 SUBD F0,F10,F12 MULD F14,F0,F10
and suppose DIVD F0,F2,F4 were in reservation station 3 ...
... and SUBD F0,F10,F12 were in reservation station 4.
The in the hardware, ADDD would use 3 to identify operand F0 ...
... while MULD would use 4 to identify operand F0 ...
... thus avoiding anti-dependency between ADDD and SUBD.
In ID instruction reads registers in usual way ...
... a free reservation station is chosen based on instr. opcode ...
... instruction moves to reservation station at end of cycle.
Value actually read from register may be ...
... a register value (the normal case) ...
... or a reservation station number.
Functional unit outputs, using a common data bus, connect to ...
... register storage ...
... and reservation stations.
When a functional unit has a result ready ...
... it gains control of the bus ...
... and places the value and the instruction reservation station number on the bus.
All reservation stations watch this bus ...
... so they can replace reservation station numbers in their operand fields with the appropriate values (if necessary).
Moving back to the ID stage ...
... when a reservation station is chosen for an instruction ...
... the reservation station number is written into the register file ...
... replacing the value held in the destination register.
Writes to the register file are done when ...
... a result is placed on the common data bus ...
... and the reservation station number on the bus matches one stored in the register file.
Note: When reading this the second time, be sure not to confuse a reservation station with the numbers of other reservation stations possibly stored in operand fields.
Practicality of Tomasulo's Approach
It's practical (unavoidable may be a better word) for ISAs that have a small number of registers because a programmer cannot rename registers (as was done in the loop example above) without soon running out of registers.
Is also practical in conjunction with other aggressive techniques ...
... such as multiple issue and speculative execution.
| David M. Koppelman - koppel@ee.lsu.edu | Modified 8 Apr 1997 9:44 (14:44 UTC) |