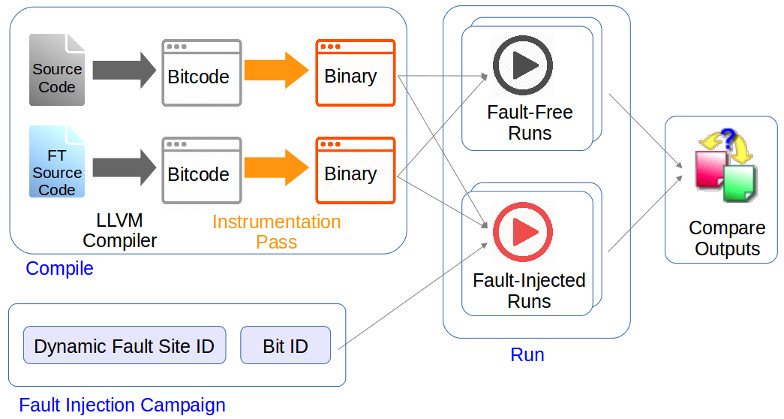
Due to hardware processes shrinking to several nanometers and the scaling up of Big Data analytics infrastructure, the threat of soft error-induced bit flips pose threats on Big Data analytics applications that cannot be ignored. Handling these threads requires exploration on multiple fronts: understanding of algorithms will be conducive to efficient error correction, while understanding of scaling-up will be helpful for efficient checkpointing, which can help error recovery. This page provides the experiment tools that can be used for such exploration.
The Eight Kernels
We have chosen eight kernels from BigDataBench, performed fault injection experients and added resilience techniques to them. The experiment results have shown that these kenrels may be made fault tolerant with a combination of algorithm-level invariants and low-level invariants. The details of the fault resilience techniques are described in [1].
Matrix-Matrix Multiplication
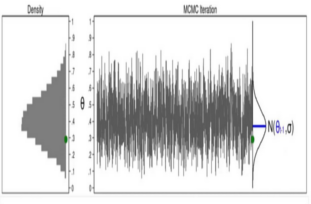
Metropolis-Hastings MCMC Sampling
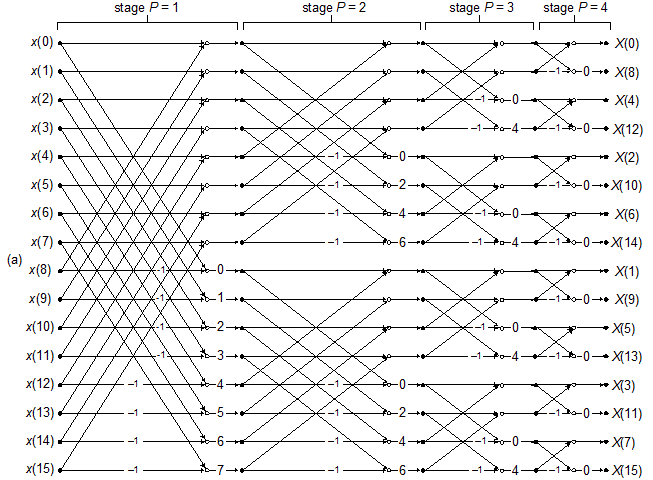
Fast Fourier Transform
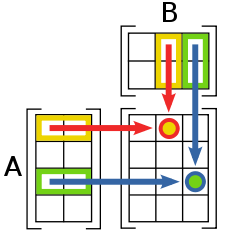
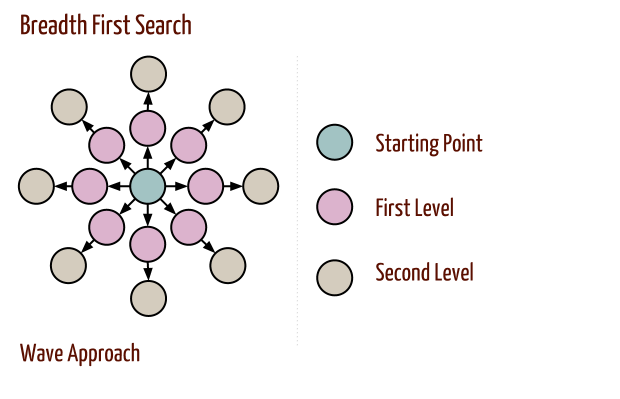
Breadth First Search (BFS)
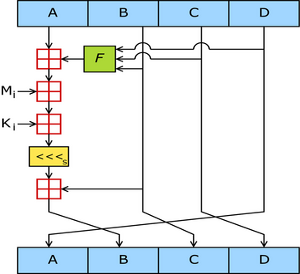
MD5 Hash
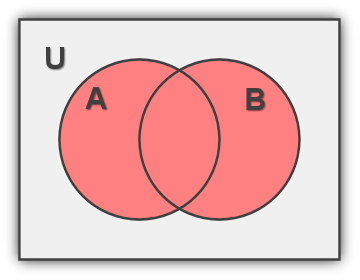
Set Union
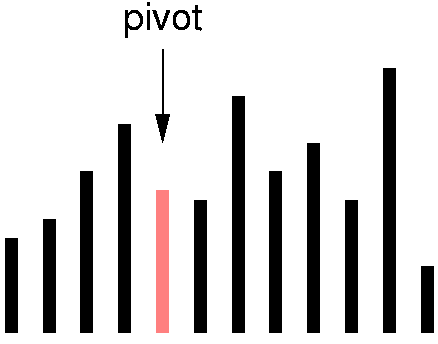
Quicksort
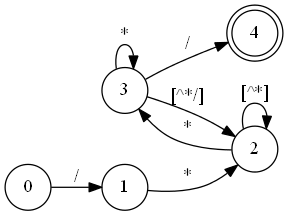
GREP
Fault injection experiments are performed on the original kernels and fault-resilient kernels to introduce bit-flip errors during run-time. Multiple experiments are performed, with one bit-flip error per run. The results are aggregated to form a comparison and evaluated using kernel-specific error metrics to form a comparison between the original and fault-resilient kernels. Details of the experiments are discussed in [1].
Fault Injection Workflow
Kernel-Specific Error Metrics
The Error Metrics are used to determine for each of the kernels whether an output is correct and if it's not,
how incorrent the output is. For each of the metrics, lower is better (meaning a result is less incorrect.)
Kernels
Metric
Matrix Multiplication and FFT
RMS error between faulty and golden outputs
Metropolis-Hastings MCMC
Absolute error between mean of generated samples
Set Union, Quicksort
Number of misplaced elements
Grep
Difference in number of occurrences of the searched pattern
MD5 Checksum
Whether the output equals the golden output
File Download
The Big Data Kernels come with two versions: a version with fault inejction and a version without fault injection.
For the version with fault injection, the kernels need to be compiled and instrumented through LLVM in order to enable fault injection experiments:
The next sections contain directions to how to compile the fault injection framework, how to compile the kernels, and how to use the input generator.
If you use this set of Big Data kernels in your work, please kindly cite [1]. Thanks for your interest!
Building the Fault Injector
The ``Fault Injector'' includes both the Fault Injection binary transform LLVM pass (which is derived from the KULFI fault injector from University of Utah), LLVM 3.2, as well as a run-time library. The run-time library are located in the sources of the big data kernels and are compiled into the binary, which is handled by the Makefiles there, and do not need to be compiled with the fault injection pass. This section discusses the compilation of LLVM 3.2 and the fault injection pass.
The compilation process assumed the user has GCC version 5 (g++-5). If g++-5 is not available, line 3 in the file Makefile_KULFI needs to be modified to match the available g++ version. For example, if there is only g++-4.8 present, that line should be changed into:
LLVM 3.2 is used for best compatibility (newer versions such as 3.8 should work but may take longer to build, may be using cmake rather than GNU make, and may require changing inclusion paths in the injector pass.)
It is recommended to do an out-of-source building, which means there are 3 different directories involved in the building procedure: the source directory, build directory and the installation directory. Assume they are set as following:
Source Directory:
~/llvm-3.2-src/
Build Directory:
~/llvm-3.2-build/
Installation Directory:
~/llvm-3.2-install/
The build procedure is as follows.
First extract the LLVM source to the Source Directory (so that the directory becomes the root of the source tree) and create the build directory and do the configuration step from there, setting the Installation Directory as the prefix.
$ cd ~ && mkdir llvm-3.2-build
$ cd llvm-3.2-build
$ ../llvm-3.2-src/configure --prefix=~/llvm-3.2-install
$ make -j4
The above 4-threaded build (specified using the -j4 flag) takes about 20 minutes to complete on i5-3210M.
When the build completes, do an ``install'':
$ make install
You will find the binaries in the installation path. The tools built include clang++, opt, llvm-link and llc, which will be used for compiling the Big Data Kernels:
opt is the LLVM optimizer, and its binary instrumentation capability which is conducive to optimizations is used for fault injection purposes in this project.
$ ~/llvm-3.2-install/bin/opt --version
LLVM (http://llvm.org/):
LLVM version 3.2svn
Optimized build with assertions.
Built May 15 2017 (12:09:18).
Default target: x86_64-unknown-linux-gnu
Host CPU: core-avx-i
$ ~/Downloads/llvm-3.2-installed/bin/llvm-link --version
LLVM (http://llvm.org/):
LLVM version 3.2svn
Optimized build with assertions.
Built May 15 2017 (12:09:18).
Default target: x86_64-unknown-linux-gnu
Host CPU: core-avx-i
$ ~/Downloads/llvm-3.2-installed/bin/llc --version
LLVM (http://llvm.org/):
LLVM version 3.2svn
Optimized build with assertions.
Built May 15 2017 (12:09:18).
Default target: x86_64-unknown-linux-gnu
Host CPU: core-avx-i
Registered Targets:
arm - ARM
cellspu - STI CBEA Cell SPU [experimental]
cpp - C++ backend
hexagon - Hexagon
mblaze - MBlaze
mips - Mips
mips64 - Mips64 [experimental]
mips64el - Mips64el [experimental]
mipsel - Mipsel
msp430 - MSP430 [experimental]
nvptx - NVIDIA PTX 32-bit
nvptx64 - NVIDIA PTX 64-bit
ppc32 - PowerPC 32
ppc64 - PowerPC 64
sparc - Sparc
sparcv9 - Sparc V9
thumb - Thumb
x86 - 32-bit X86: Pentium-Pro and above
x86-64 - 64-bit X86: EM64T and AMD64
xcore - XCore
The above messages suggest that LLVM-3.2 has been successfully built.
2. Injector Pass
A ``pass'', according to the LLVM documentation, is a procedure in the compiler that takes a bytecode file as input, performs transformations, optimizations and/or analyses on it, and produces a bytecode file, or some analysis results, as an output.
The particular fault injection pass we use here is a transformation pass, taking a linked program bytecode as input, and produces an instrumented bytecode as output. The instrumented bytecode has codepaths that allow introduction of bit flip errors in the results of certain types of LLVM instructions.
If you have built LLVM-3.2 before, you can find a ``lib/Transform'' directory in the Build Directory (which is created during the build process of LLVM 3.2). You need to add a subfolder in that lib/Transform (in this example, lib/Transform/faults2 is used) to acknowledges the LLVM build system of the new fault injection pass, if the folder (lib/Transforms/faults2) does not exist.
The procedure is identical to the preparatory steps before creating a new LLVM pass.
$ cd ~/llvm-3.2-build
$ cd lib/Transforms
$ ls
Hello InstCombine Instrumentation IPO Makefile Scalar Utils Vectorize
$ cp -r Hello faults2
$ ls faults2
Makefile Release+Asserts
Then, edit faults2/Makefile, such that it reads as follows. Make sure to change
LIBRARYNAME
to
faults2
and remove the line and if statements that set
EXPORTED_SYMBOL_FILE
.
##===- lib/Transforms/Hello/Makefile -----------------------*- Makefile -*-===##
#
# The LLVM Compiler Infrastructure
#
# This file is distributed under the University of Illinois Open Source
# License. See LICENSE.TXT for details.
#
##===----------------------------------------------------------------------===##
LEVEL = ../../..
LIBRARYNAME =
faults2
LOADABLE_MODULE = 1
USEDLIBS =
include $(LEVEL)/Makefile.common
Then build and install the fault injector module, similar to building and installing LLVM itself:
$ cd faults2
$ make && make install
llvm[0]: Linking Release+Asserts Loadable Module faults2.so
llvm[0]: Installing Release+Asserts Shared Library /(your home directory)/llvm-3.2-installed//lib/faults2.so
After this step, you have the fault injecting compiler infrastructure set up and are ready for the next steps.
Building and Testing Run the Big Data Kernels
There are three variants for each of the kernels:
Non-fault-injected, non-fault-tolerant
Fault-injected, non-fault-tolerant
Fault-injected, fault-tolerant
The building and compiling of each of the variants are largely the same, but the input formats/parameters and outputs may slightly differ.
Specifically, the non-fault-injected variant will not show fault-injection-specific outputs.
The table below shows the outputs from the two fault-injected variants as examples.
Choose one kernel from the list below to view the build procedure and the expected output for the test runs.
1. matrix multiplication
Non-Fault-Injected version: (The make command will compile the dependency, GSL 1.14, in its source directory. This means the library will be in the source directories, and the GSL 1.14 source directory will be added to link-time and run-time library paths.)
cd MatrixMultiplication
make # Will build GNU GSL 1.14 in source if it has not been built already
Build both fault-tolerant and non-fault-tolerant binaries:
cd Metropolis-Hastings
make ft
make nonft
Test Non-Fault-Tolerant Run:
$ ./mh.bin
Expected output:
MEAN: 13.6074
Elapsed Time: 7.129112s
>>>>>>>> Not Faulty!
/*********************Fault Injection Statistics****************************/
Total # fault sites enumerated : 2060100820
/*********************************End**************************************/
Test Fault-Tolerant Run:
$ ./mh_ft.bin
Expected output:
MEAN: 13.6074
Elapsed Time: 7.552275s
>>>>>>>> Not Faulty!
/*********************Fault Injection Statistics****************************/
Total # fault sites enumerated : 2109453962
/*********************************End**************************************/
Regarding golden output:
A golden output is not used for testing faultiness in the program. It is assumed to be 13.6074 when aggregating experiment results and determining the outcomes of individual runs.
3. Fast Fourier Transform
Non-Fault-Injected version: (The make command will compile the dependency, GSL 1.14, in its source directory. This means the library will be in the source directories, and the GSL 1.14 source directory will be added to link-time and run-time library paths.)
cd FFT
make # Will build GNU GSL 1.14 if it hasn't been built already
Each run writes its output to "results.txt". To use this output as a golden output, rename it into "g_results.txt".
8. GREP
Non-Fault-Injected version:
cd Grep
make
Test run: (No need to specify the NEXT_FAULT_COUNTDOWN needed for non-fault-tolerant runs)
$ ./mpi_grep.bin -i SmallInput/lda_wiki1w_1 -p a
Expected output:
###file
Total Count: 4389255
wall clock time = 0.624124
Fault-Injected versions:
Build both fault-tolerant and non-fault-tolerant binaries:
cd Grep
make nonft
make ft
Test Non-Fault-Tolerant Run:
$ NEXT_FAULT_COUNTDOWN=10000000000 ./mpi_grep.bin -i SmallInput/lda_wiki1w_1 -p a
Expected output:
###file
Total Count: 4389255
wall clock time = 0.310948
/*********************Fault Injection Statistics****************************/
Total # fault sites enumerated : 40834205
/*********************************End**************************************/
Test Fault-Tolerant Run:
$ NEXT_FAULT_COUNTDOWN=10000000000 ./mpi_grep_ft.bin -i SmallInput/lda_wiki1w_1 -p a
Expected output:
###file
Total Count: 4389255
wall clock time = 0.504524
>>>>>>>> Not Faulty!
/*********************Fault Injection Statistics****************************/
Total # fault sites enumerated : 103768175
/*********************************End**************************************/
Regarding golden output:
Similar to MCMC, the output is a single number. Therefore, it is not saved into a file, and is treated similar to a return value when performing result analysis.
Input Generation
The following shows the steps to generate inputs that take about 1 minute to run on an i5-3210M processor. Depending on the kernel, inputs may be generated with a script, or the Graph Generator / Text Generator of the Big Data Generator Suite in BigDataBench (we include the versioned that's been modified for compatibility in the Download section.) The parameters may be changed for larger/smaller inputs.
1. Matrix Multiplication
First, go to the source directory of Matrix Multiplication and modify the CONFIG file such that it reads as follows:
M=800
N=700
P=600
Then type the following (the first command builds the input generator):
bash BUILD_INPUT_GENERATOR
./mm_gen writefile
This will create 3 matrices with 800x700, 700x600 and 800x600 sizes, stored in ./ft3_data/.
The input files need not be specified when running the kernel. Just change directory to where ft3_data is located and run the program:
./MM.out
./MM_FT.out
2. Metropolis-Hastings MCMC
This kernel does not take an input file. All it takes is an input parameter for the sample size. A one-minute run is done as follows:
./mh.bin 100000
./mh_ft.bin 100000
3. FFT
Input generation for FFT is similar to that for Matrix Multiplication. Go to the source directory of FFT and modify the CONFIG file such that it reads:
FFTSize=33554432
Then type the following (The first command builds the input generator):
bash BUILD_INPUT_GENERATOR
./fft_gen writefile
This will create an input file stored in ./ft3_data/.
The input files need not be specified when running the kernel. Just change directory to where ft3_data is located and run the program:
./FFT.out
./FFT.outFT
4. BFS
Inputs to BFS are generated using the Graph Generator in the Big Data Generator Suite.
$ NEXT_FAULT_COUNTDOWN=100000000000 ./mpi_grep_ft.bin -i $HOME/Downloads/BigDataGeneratorSuite/Text_datagen/gen_data/AMR1_noSW_95_Sampling_1 -p e
Fault Injection
The fault injector is designed to inject a single bit flip error into one dynamic instruction (also referred to as a "fault site") in a program run. To perform fault injection, set the environment variable ``NEXT_FAULT_COUNTDOWN'' and run the instrumented binary.
For example, this command sets a "countdown" of 2585333 to the dynamic instruction that is to be fault-injected:
NEXT_FAULT_COUNTDOWN=2585333 ./qsort.bin
When executed, you will see an output that consist of 3 parts:
$ NEXT_FAULT_COUNTDOWN=2585333 ./qsort.bin
[Fault Injection Campaign details]
Max interval: 10000000
Reading configuration from environment variables.
Next fault CountDown = 2585333
Should initialize randseed = 0
Bit position for faults=-1
Dump BB Trace=0
Part 1 of the output simply shows the fault injection campaign (only the countdown to the next fault is utilized; the fault injection run-time has some other features that are not used in this project.)
/*********************************Start**************************************/
Succeffully injected 32-bit Int Data Error!!
Total # faults injected : 1
Bit position is: 7
Index of the fault site : 2856
Total # of fault sites enumerated: 2585334
/*********************************End**************************************/
Part 2 of the output is printed when a fault is actually injected into the program, which includes some details about the current fault-injected run:
- The total # faults line suggests 1 bit-flip error has been introduced so far, which is the error that's been just injected.
- The bit position line suggests the 8th bit (the position is zero-based) has been flipped, which is equivalent to XOR'ing the output of the fault injected instruction with (1<<7).
- The index of the fault site line indicates the ID of the static fault site, namely, the static LLVM instruction.
- The total # of fault sites enumerated line indicates that a total of 2585334 fault sites have been enumerated. (The number may be slightly different from the specified Countdown.)
The last part of the output contains the rest of the program output as well as the fault injection summary.
- "FAULTINESS: 85" is the output from the proram-specific error check. In Quicksort, this means 85 elements in the output are located at incorrect places.
- The last line prints out the number of dynamic fault sites that have been enumerated in this fault-injected run. Because a fault injection may cause the control flow of a program to change, this number may be different from that of a non-fault-injected run, or another fault-injected run.
The size of the entire fault injection space could be prohibitively large, so usually a subset of the space is sampled. Details of the process of sampling and making sure the sample size is large enough to be representative of the characteristics of the kernel in question are discussed in [1].
References
Please kindly cite the following paper as your reference if you are using the kernels for your work.