This plot shows efficient of a loop.
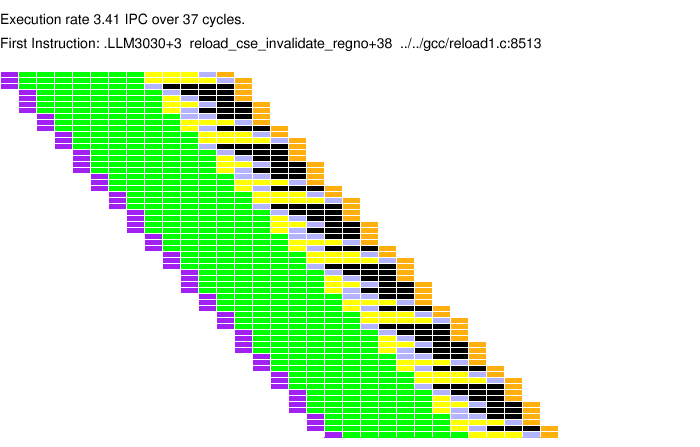
The plot above shows instruction states in pipeline execution diagram (PED) form with dynamic instructions (instructions in program order) plotted along the vertical axis and time (in cycles) along the horizontal axis.
An instruction is shown by a horizontal set of rectangles, the color of each rectangle shows the state at a particular cycle. Each vertical line of rectangles shows the state of all instructions in flight at that cycle.
Notice that at each cycle either three or four new instructions enter the processor and either two or four leave.
If might be helpful to think of this as fetch, but it's not. The simulator currently does not provide fetch state information.
The systems simulated have a large number of functional units so this state usually indicates execution.
The system simulated is four-way superscalar and can fetch at most four instructions per cycle, but in the illustrated portion sometimes only three instructions are fetched. This is due to a branch in the group of three instructions. (The simulated processor cannot fetch a branch and its target in the same cycle.) The system here is able to fetch 3.333 instructions per cycle, the fetch rate can be alot worse.
Notice that most of the time for an instruction is in decode- and scheduling-related activities (green), while the to perform the actual arithmetic (blue) (at least for integer instructions) is just one cycle. Wouldn't airports be alot simpler if the taxi could just drop you off right at your airplane?
Yellow indicates instructions that are waiting for a result from preceding instructions. (There is a dependency with an earlier, not-yet-complete instruction.) In a statically scheduled processor such instructions would stall the pipeline, resulting in lower performance. The dynamically scheduled system simulated here handles these instructions easily. Ideally, the compiler would schedule code to avoid instructions waiting for dependencies. Clearly the scheduling in the compiler used for the benchmark, gcc 2.95.2 was not sufficient. (The gcc compiler is not known for generating the best code. Other output samples were compiled with Sun's compiler, which is better.)
Black shows completed instructions waiting to commit. The four-way processor can commit at most four instructions per cycle and must commit them in order, which is why completed instructions hang around.
The loop illustrated here is efficient for the following reasons. Nearly four instructions per cycle are being fetched. Fewer instructions might be fetched because of branch alignment and mispredictions by the next-line predictor and branch predictor, and instruction cache misses.
There is enough instruction level parallelism to allow 3.333 instructions per cycle to execute using a small window. If there were more ILP there would be no yellow at all, in such a code fragment an instruction would only use results from instructions fetched earlier (as opposed to the two or three instructions fetched at the same time). In the worst case each instruction would use the result produced by the immediately preceding instruction, resulting in an IPC no higher than 1.