Demo 1: Bouncing Ball
Shows a ball boncing on a plane. Dynamic state is just the ball position and velocity.
Code used in class. The links below may point to out-of-date copies, use anonymous git to retrieve the latest copies at git://dmk.ece.lsu.edu/gp. (GIT documentation.)
Shows a ball boncing on a plane. Dynamic state is just the ball position and velocity.
The code shows examples of how to use the data types, but does not do anything useful.

The hierarchical construction of objects. Each object is constructed in its local coordinate space by instantiating and positioning other objects. The positioning is done by setting a transformation matrix.
Demonstrate different material properties (emissive, ambient, diffuse, specular) and lighting options.
Demonstrate use of vertex arrays and buffer objects, which are much faster ways of sending vertex data to OpenGL than using glVertex to send the data one vertex at a time. Also shows benefit of pre-computing coordinates.
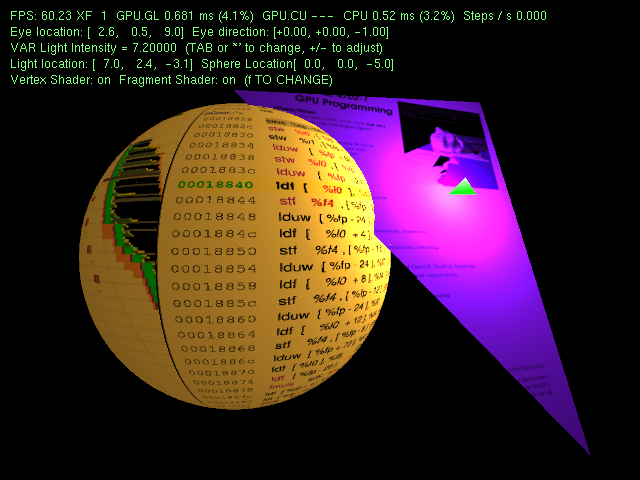
Demonstration of vertex and fragment shader for per-fragment lighting calculations. Also look at and the shader code.

Demonstration of vertex shaders for computing vertex points, including simple animation. Demonstration of reading buffer objects as arrays (shader storage buffers). Demonstration of using geometry shader. Also look at the shader code here and here.
A very simple CUDA program. No graphics.
Demonstration of efficient memory access patterns. Code computes the magnitudes of an array of vectors. No graphics.
Example demonstrates use of shared memory. Code computes the average of the magnitudes of a list of vectors. Shared memory within a block is used to find the sum of the magnitudes witin a block. No graphics.
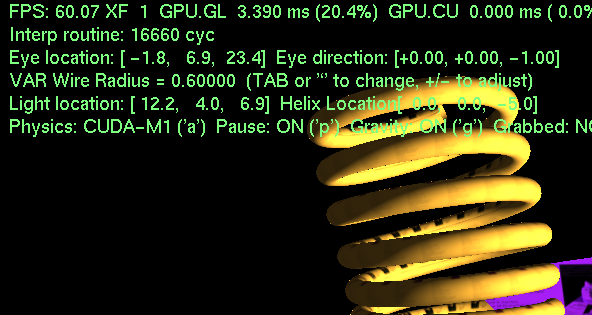
The comments describe key concepts of memory access patterns and thread assignment that must be clearly understood. Demonstration of efficient global memory access patterns for code of the form: for (i=0; i<size; i++) for (j=0; j<size; j++) something(a[i],a[j]); . Comments in code show how array elements determined from threadIdx and blockIdx. Also see the host (CPU) code and the header file.
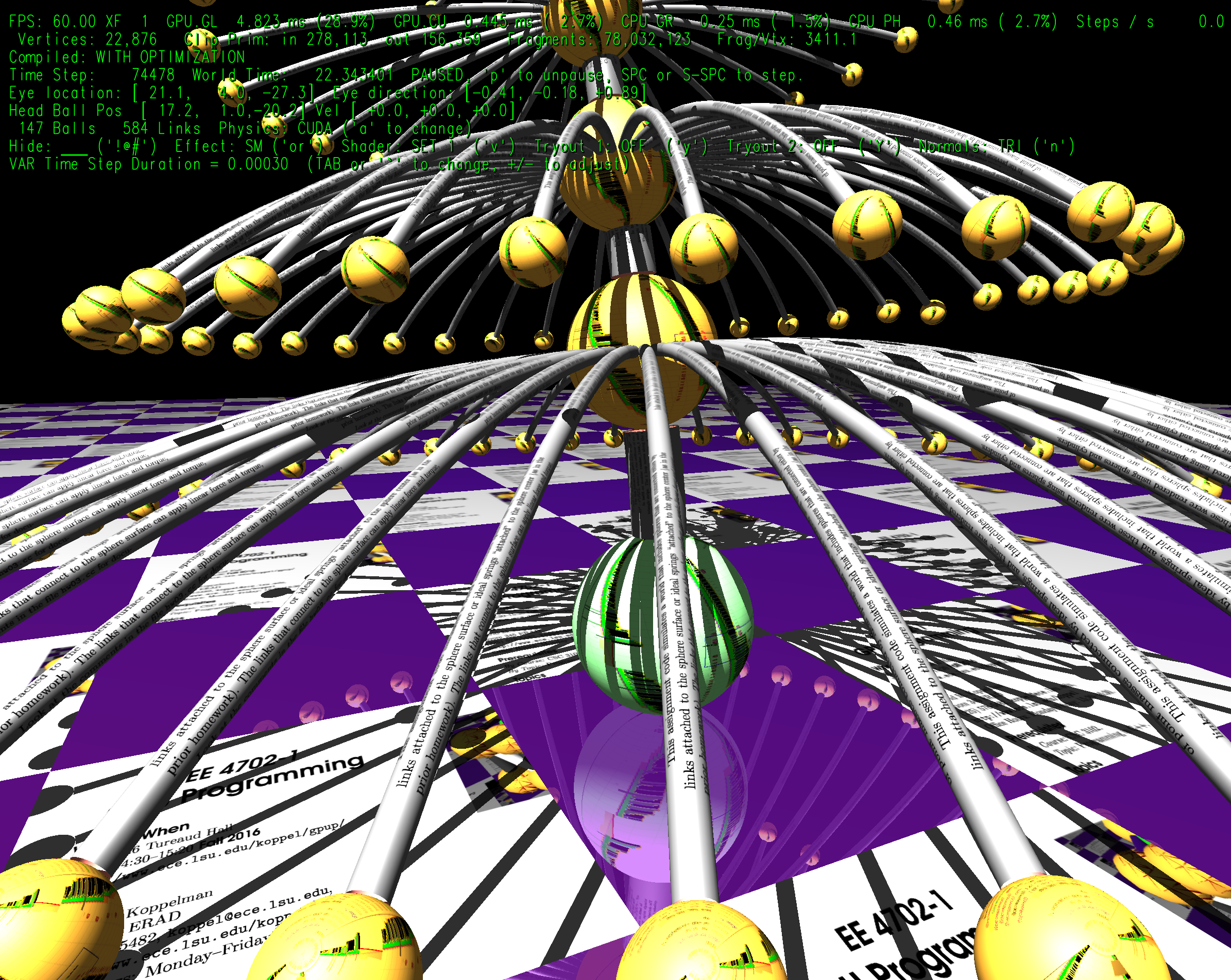
The code simulates systems made of spring and point masses, rendered to look like spheres and curved cyclinders. Shader code is used for the curved links, among other effects, and CUDA code is used for the physics.
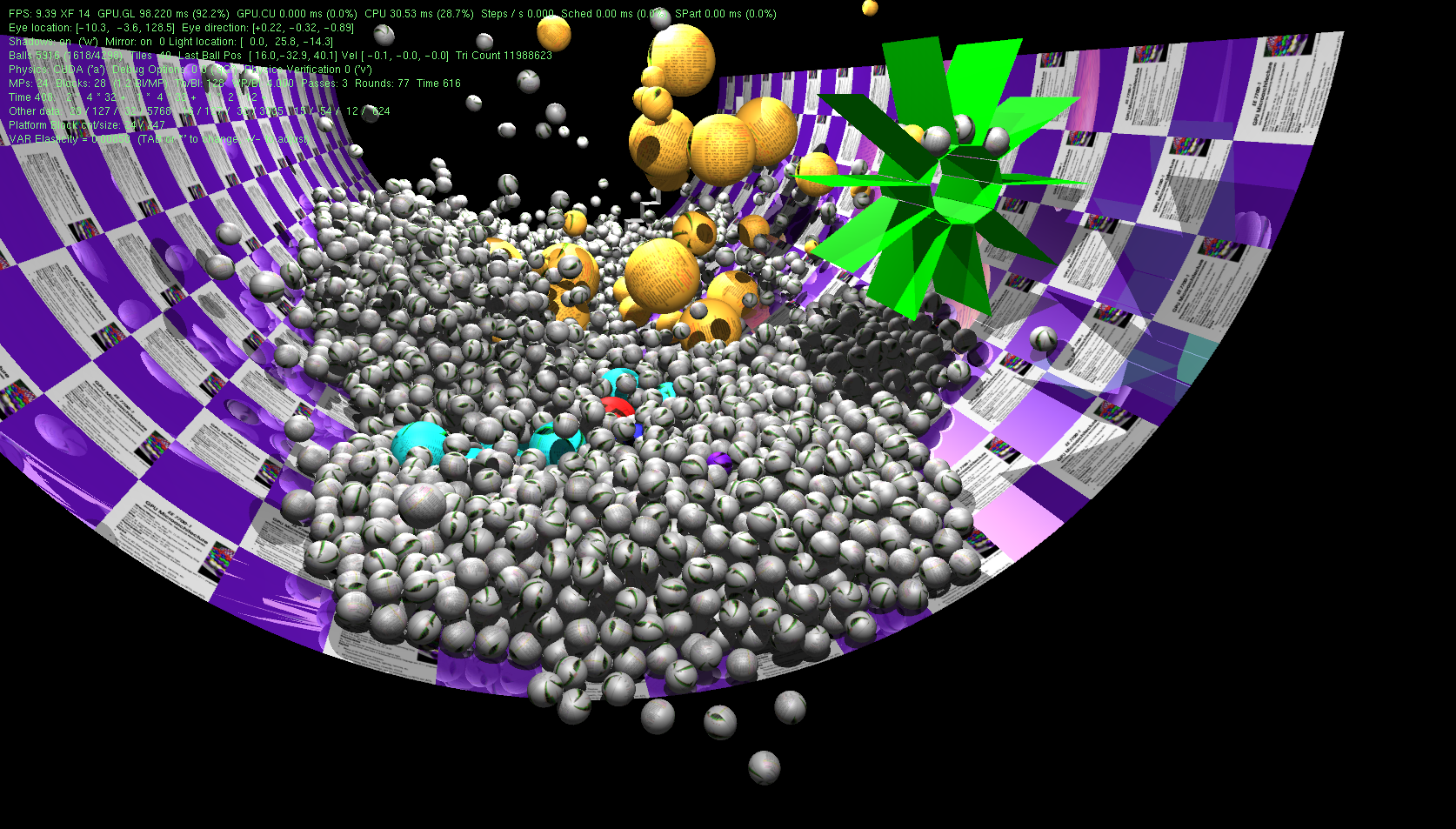
This code, for use as a project base and in-class demo, shows multiple techniques. These include: ball physics performed by GPU via CUDA, use of shadow volumes to stencil shadow locations, use of vertex and geometry shader to compute ball reflection locations, use of occlusion queries to limit the number of balls rendered. See also CUDA code, and Shader code.

File location: git://dmk.ece.lsu.edu/gp/proj-base/boxes. This code, for use as a project base and in-class demo, shows multiple techniques. These include: physics on spheres (balls) and boxes performed by the GPU via CUDA, use of shadow volumes to stencil shadow locations, use of vertex and geometry shader to compute ball reflection locations, use of occlusion queries to limit the number of balls rendered.
| David M. Koppelman - koppel@ece.lsu.edu | Modified 28 Jun 2023 14:02 (1902 UTC) |
| Provide Website Feedback • Accessibility Statement • Privacy Statement |