
0 1 2 3 4 19 20
mems IF ID EX1 MEM1 MEM1 ... MEM1 MEM1 MEM2 WB
EX2 EX2 EX2 EX3
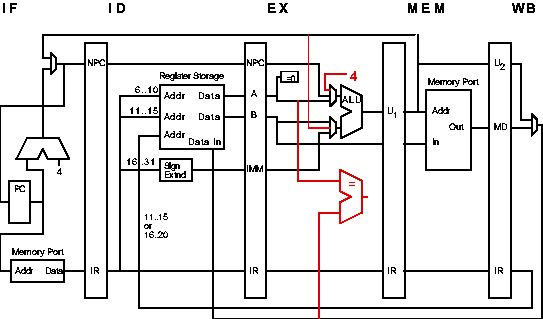
As usual, the instruction is fetched in IF. In ID rs1 (e.g., r1) is
loaded into latch buffer A and rs2 (e.g., r2) is loaded into B. The
EX stage is used three different ways, EX1, EX2,
and EX3. In EX1 the address, rs2, is passed
through the ALU unchanged. The ID/EX latches are not clocked until
the cycle after the element is found, so that rs1 is held in the B
buffer. (rs2 is also held, but is not needed.) In MEM1 the
element is retrieved from memory while at the same time the address of
the next element is computed in EX2. Using an added
comparison unit, EX2 also compares the element retrieved in
the previous cycle with rs1. The mems instruction will continue using
the EX and MEM stages (inserting NOPs into WB and stalling
instructions in IF and ID), until the comparison unit signals a
match (cycle 19 in the example).
In the cycle following a match (20) the execute stage performs
EX3, subtracting 4 to compute the address of the element
found in the previous cycle. The address makes its way back to rs2 in
MEM2 and WB.
LOOP: lw r3, 0(r2) addi r2, r2, #4 ! Words are four bytes long. seq r3, r3, r1 ! Compare. Note that lw stall avoided. beqz r3, LOOP subi r2, r2, #4 ! Saves a branch inside or before loop.
An iteration of the program above executes as follows (on a implementation that includes bypass paths)
0 1 2 3 4 5 6 7
lw IF ID EX MEM WB IF
addi IF ID EX MEM WB
seq IF ID EX MEM WB
beqz IF ID EX MEM WB
Each iteration takes seven cycles, one additional cycle is needed
after the last iteration to complete the subtraction.
The total number of cycles is 7 × 1000 + 1 = 7001.Advanced techniques, covered in chapter 4, will reduce mems advantage.
0 1 2 3 4
lw IF ID EX MEM WB
add IF ID EX WB
The hazard occurs in cycle 4.
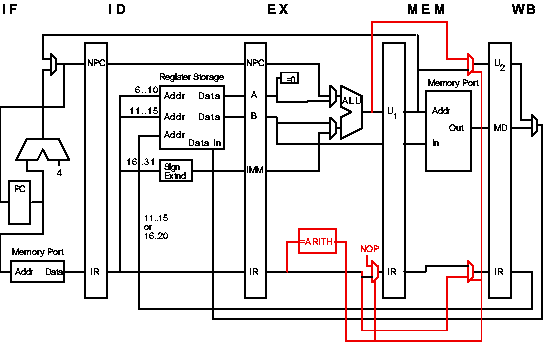
The problem is avoided if undefined instructions raise an illegal instruction exception.
The target address of a trap instruction is typically in the system part of the address space while subroutines are in the user part.
As a result of executing a trap, the processor switches to privileged mode, while subroutine calls do not change the processor mode.
The instruction count might change in two implementations of the same ISA because relative execution times for individual instructions might change (although the instructions available in the old and new implementations are the same), leading programmers to re-write time-critical portions. For example, an integer add might be replaced by a speeded-up floating-point add, perhaps saving integer-to-floating-point and floating-point-to-integer conversion steps.
CPI might change because the number of stall cycles was reduced using advanced techniques, etc.

| David M. Koppelman - koppel@ee.lsu.edu | Modified 17 Mar 1998 17:31 (23:31 UTC) |